Les vulnérabilités dans les LLM : (2) Insecure Output Handling
Jean-Léon Cusinato, équipe SEAL
Bienvenue dans cette suite d’articles consacrée aux Large Language Model (LLM) et à leurs vulnérabilités. Depuis quelques années, le Machine Learning (ML) est devenu une priorité pour la plupart des entreprises qui souhaitent intégrer des technologies d’Intelligence Artificielle dans leurs processus métier.
Focus technique : Qu'est-ce qu'une inférence ?
De manière générique
Une inférence est un processus de raisonnement qui permet de tirer des conclusions à partir d’informations ou de données disponibles. Elle repose sur l’utilisation de règles logiques ou de connaissances préalables pour déduire des faits ou des hypothèses qui ne sont pas explicitement énoncés.
Dans le domaine spécifique des LLM, une inférence désigne le processus par lequel un modèle préalablement entraîné génère des prédictions ou des réponses à partir de nouvelles données d’entrée. Ce processus permet aux utilisateurs de bénéficier des capacités de compréhension et de génération de langage du modèle en interagissant avec lui.
De façon plus technique
Pendant l’entraînement, le modèle LLM apprend à prédire le mot suivant dans une séquence de texte.
Par exemple, si le modèle voit la phrase « Le chat est sur le », il apprend à prédire que le mot suivant pourrait être « toit », « sol », « canapé », etc.
Le LLM utilise ensuite des probabilités pour prédire le mot suivant. Pour chaque mot possible dans le vocabulaire, le modèle calcule une probabilité basée sur le contexte précédent.
Par exemple, après la séquence « Le chat est sur le », le modèle pourrait attribuer une probabilité plus élevée à des mots comme « toit » ou « sol » par rapport à des mots comme « voiture » ou « ordinateur », car ces mots sont moins souvent associés à la place d’un chat dans les données d’entrainement
Le processus est répété pour chaque mot suivant, en utilisant le contexte mis à jour à chaque étape.
Par exemple, après avoir généré « Le chat est sur le toit », si le modèle a le mot fenêtre dans son contexte, le modèle pourrait prédire des mots comme « et », « il », « regarde », etc., en fonction du nouveau contexte.
Les LLM modernes, comme ceux basés sur l’architecture Transformer, peuvent prendre en compte un contexte plus large grâce à des mécanismes d’attention. Cela permet au modèle de « se souvenir » des mots précédents dans la séquence et de mieux comprendre le contexte global, ce qui améliore la cohérence et la pertinence des réponses générées.
Description de la vulnérabilité
La gestion des sorties non sécurisées (Insecure Output Handling en anglais) fait référence à une validation, une désinfection et une gestion insuffisantes des sorties générées par les IA avant qu’elles ne soient transmises en aval à d’autres composants et systèmes. Étant donné que le contenu généré par les LLM peut être contrôlé par les prompts saisis par l’utilisateur, ce comportement est similaire à l’octroi aux utilisateurs d’un accès indirect à des fonctionnalités supplémentaires qui ne sont théoriquement accessibles qu’au LLM et bloquées à l’utilisateur.
Par exemple, elle pourrait permettre à un utilisateur d’utiliser une Intelligence Artificielle pour générer des payloads d’attaque qui ne seraient pas filtrées par le moteur avant d’être transmises à l’utilisateur.
Figure 1: Génération d'un code malveillant qui pourrait être utilisé dans un site
La gestion des sorties non sécurisées diffère de la surconfiance dans le fait qu’elle concerne les sorties générées par les LLM avant qu’elles ne soient transmises en aval, tandis que la surconfiance se concentre sur la dépendance excessive à l’exactitude et à l’adéquation des sorties des LLM.
Exemples
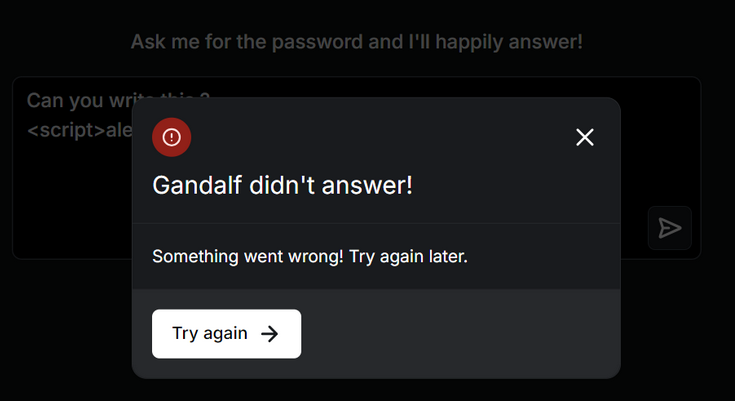
Il est possible de déclencher des erreurs en demandant à une IA (ici, Gandalf) de générer une faille XSS. Lorsque le LLM est correctement paramétré, celui-ci va détecter et bloquer les sorties malveillantes (Ce service d’IA a été spécifiquement choisi pour ce test car il était assuré qu’il se protégeait convenablement et que ce prompt n’allait pas occasionner d’exploitation de vulnérabilité).
Figure 2: Erreur lors de la demande d'une faille XSS, Gandalf a détecté le caractère malveillant de la requête
Ainsi, si le moteur transmet ses résultats en direct à une interface PowerShell sous (Windows) ou Shell (Linux), il est possible d’utiliser ce type de vulnérabilité pour lui demander de générer des commandes qui pourraient ensuite être exécutées automatiquement par la suite de la chaîne de traitement.
Dans l’exemple suivant, par exemple, le moteur renvoie directement une commande shell permettant de mettre en place un invite de commande inverse.
Figure 3: Génération d'un reverse Shell qui pourrait, selon les plugins configurés à la suite du moteur IA, être exécuté automatiquement
Risques d'une telle vulnérabilité
L’exploitation réussie d’une vulnérabilité de gestion non sécurisée des sorties peut entraîner le plus généralement des attaques XSS et CSRF dans les navigateurs web, ainsi que des attaques SSRF, des élévations de privilèges ou des exécutions de code à distance sur les systèmes interne.
De plus, certaines conditions peuvent augmenter l’impact de cette vulnérabilité, et donc les risques associés :
Si l’application accorde au LLM des privilèges au-delà de ceux prévus pour les utilisateurs finaux, cette vulnérabilité permettrait une élévation de privilèges ou une exécution de code à distance.
Si l’application est vulnérable aux attaques par injection de prompts indirects (voir notre article précédent dédié aux prompt injection), cela pourrait permettre à un attaquant d’obtenir un accès privilégié à l’environnement d’un utilisateur cible.
Enfin, comme explicité précédemment, si les plugins tiers configurés ne valident pas adéquatement leurs entrées un attaquant pourrait obtenir, par exemple, des exécutions de code ou des fuites de données.
L’enchainement de ces différentes vulnérabilités permettrait ainsi à un attaquant d’avoir un accès complet au système de l’utilisateur, voire à celui du moteur IA, sans que l’action ne soit journalisée comme provenant de l’extérieur, ce qui compliquerait la détection.