
27/06/2024
Blog technique
Breizh CTF 2024 – write ups | Part 1
Jean-Léon Cusinato

Amossys et Almond ont participé à la 8ème édition du Breizh CTF qui s’est déroulée du 17 au 18 mai 2024 à Rennes. Il s’agit d’une compétition de sécurité informatique de type « Capture the Flag » (CTF), ouverte à tous (professionnels, étudiants ou passionnés). Des équipes composées de 5 personnes s’affrontent et doivent résoudre un certain nombre d’épreuves visant à exploiter des vulnérabilités dans plusieurs domaines de la cybersécurité, comme la cryptographie, le cracking, l’exploit de binaires, le Web ou encore le forensic. A travers cet article, plusieurs write ups détaillant notre méthode de résolution de challenges et la façon dont nous les avons abordés sont présentés.
1. Allsln.exe
Information sur le challenge
AllIsIn.exe nous est fourni. Le premier pas consiste à l’analyser avec Detect It Easy: 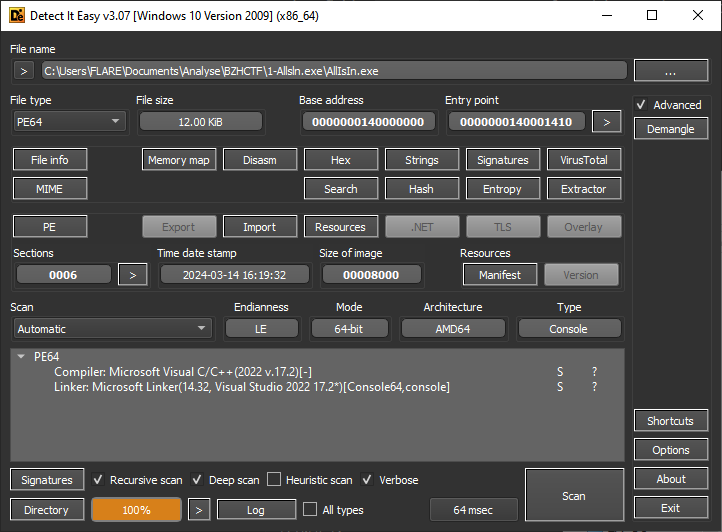
Le fichier est bien un simple PE, c’est le premier challenge. Aucun piège particulier ne semble présent au premier coup d’œil.
Résolution
Étape 1: Analyse avec IDA Pro
On ouvre le fichier et on obtient le code décompilé suivant :
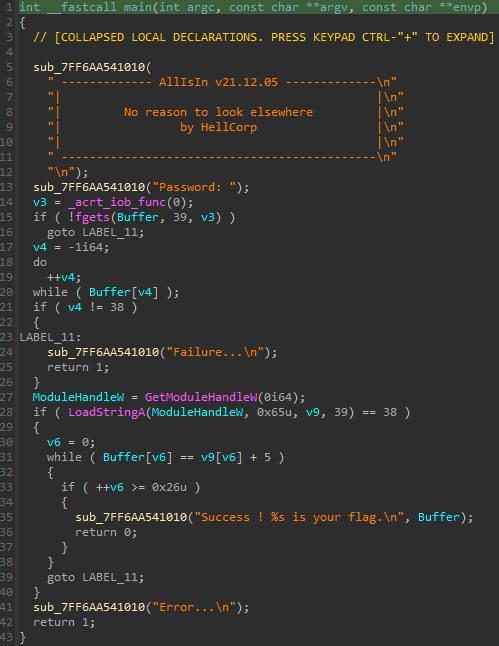
On peut voir la fonction fgets au début, demandant à l’utilisateur d’entrer une chaine de 38 caractères maximum (39, moins le caractère \0).
Ensuite, une boucle permet de mesurer la longueur du buffer et de stocker le résultat dans v4. La longueur est ensuite comparée à 38, et si elle est différente, on obtient un échec.
Sinon, le programme charge une chaine de caractères dans ses ressources, vérifie que sa longueur est de 38 aussi. Ensuite, le programme compare chaque caractère de notre chaine entrée précédemment avec la chaine dans les ressources en ajoutant 5 à chaque caractère.
Si jamais les chaines sont identiques, alors on obtient un succès, et le programme confirme que notre chaine entrée est bien le flag.
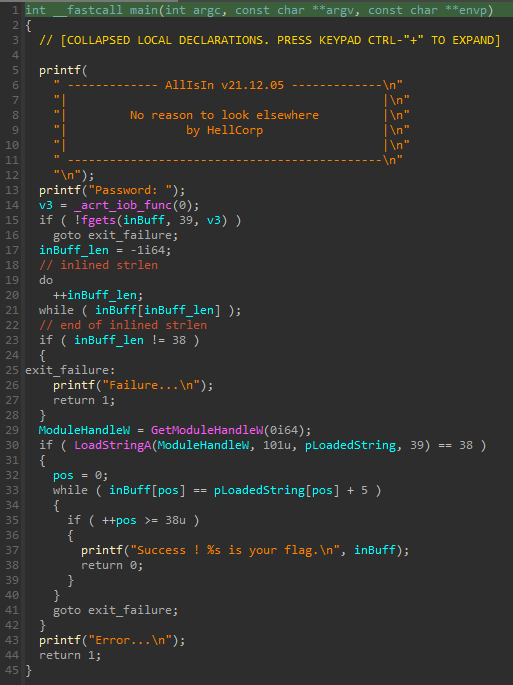
Pour ce premier WU, un exemple commenté du main est présenté ci-dessous :
Étape 2 : Localisation de la table des chaînes
string table). Cette table est souvent utilisée pour stocker des chaines de texte qui sont utilisées par l’exécutable.
Detect It Easy permet de facilement récupérer cette chaine dans les ressources. 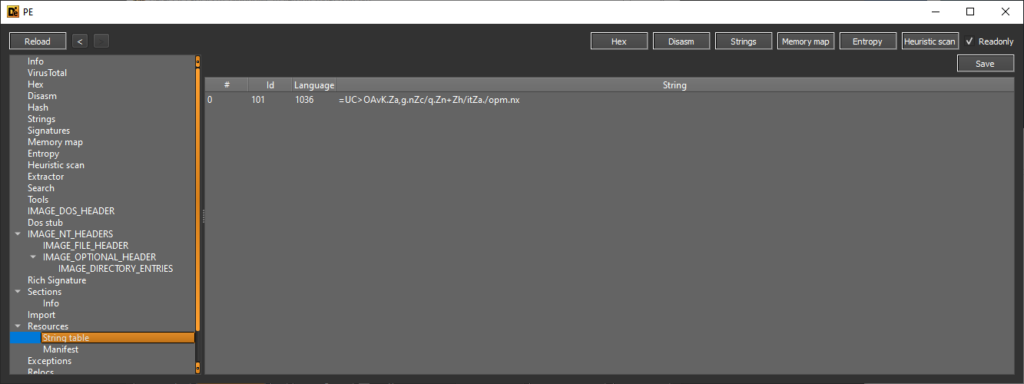
Étape 3 : Modification du mot de passe
Après avoir extrait le mot de passe, nous devons l’ajuster en ajoutant 5 à chaque caractère. Cela signifie que pour chaque caractère dans la chaine, nous calculons sa valeur ASCII, ajoutons 5, puis convertissons le résultat de nouveau en caractère.
Pour cela, nous pouvons utiliser cyberchef :

Donc =UC>OAvK.Za,g.nZc/q.Zn+Zh/itZa./opm.nx devient BZHCTF{P3_f1l3s_h4v3_s0_m4ny_f34tur3s}
Étape 4: Validation du challenge
On peut maintenant entrer ce mot de passe, et vérifier si nous n’avons rien raté, et obtenons bien un succès.
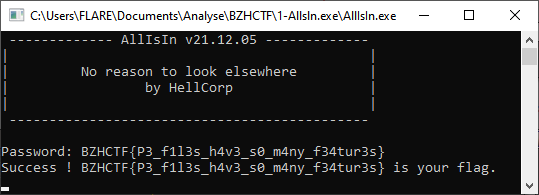
Conclusion
Ce premier challenge, bien que très simple, peut déjà bloquer quelques personnes n’ayant pas l’habitude de travailler sur des fichiers PE. L’utilisation de la MSDN pour étudier les fonctions importées, comme LoadStringA peut permettre à n’importe qui avec des bases de rétro ingénierie et les bons outils de résoudre ce challenge en moins de 30 minutes.
2. CantFollow
Information sur le challenge
CantFollow nous est fourni. Le premier pas consiste à l’analyser avec Detect It Easy: 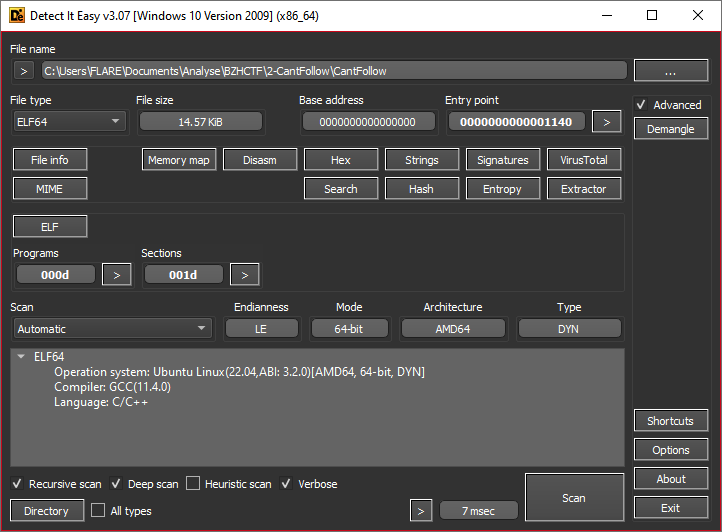
On a ici un fichier binaire exécutable Linux, en 64 bits. Le fichier est linké de façon dynamique, donc les fonctions de base comme printf, malloc et équivalent seront déjà identifiées lors de la décompilation. Bonne nouvelle !
Résolution
Étape 1 : Analyse avec IDA Pro
(La base de données sera déjà commentée afin de gagner du temps, le main n’est pas aussi détaillé à l’origine.)
Au lancement de la décompilation, on se retrouve avec ce main :
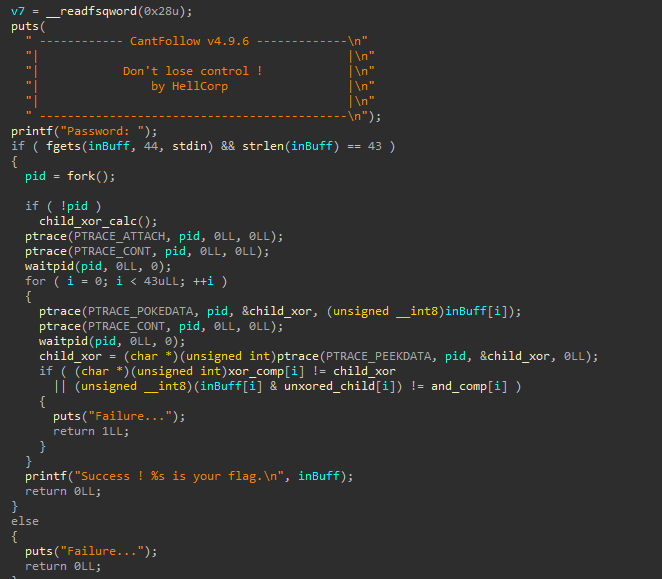
if (!pid). Ensuite, de nombreuses commandes ptraces sont présentes… On a donc un système antidebug. En effet, tous les débogueurs et traceurs de programmes utilisent l’appel ptrace pour configurer le débogage d’un processus. Si le code du débogué lui-même contient un appel ptrace avec le type de requête PTRACE_TRACEME, cela définira le processus parent comme traceur. Cela signifie que si un débogueur est déjà attaché au débogué, l’appel ptrace dans le code du débogué échouera. Cette méthode peut être contournée en utilisant LD_PRELOAD, qui est une variable d’environnement définie sur le chemin d’un objet partagé. Cet objet partagé sera chargé avant les autres bibliothèques. Par conséquent, si cet objet partagé contient votre propre implémentation de ptrace, alors votre propre implémentation de ptrace sera appelée à la place.
Dans notre cas, le débogueur déjà attaché au programme est notre programme lui-même avec le fork ! En regardant ce que fait l’enfant, on se retrouve avec cette fonction. 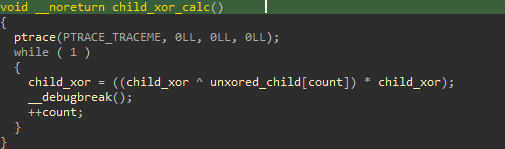
L’enfant attend donc d’être tracé, puis effectue un calcul à base de xor et de multiplications, attend que le débogueur lui dise de recommencer, et effectue le même calcul sur le caractère suivant.
Du côté du parent, on peut voir qu’une boucle est effectuée sur chaque caractère, avec un POKEDATA, modifiant la valeur de child_xor dans l’enfant avec le prochain caractère du mot de passe initialement entré. Ensuite, le parent attend que l’enfant ait effectué son calcul, puis récupère le résultat du calcul avec PEEKDATA.
Ensuite, le résultat est comparé avec un buffer (ici appelé xor-comp), et le buffer initial subit une opération AND avec unxored_child (le même buffer que dans le calcul de l’enfant) puis comparé avec un buffer appelé ici and_comp.
Si l’une de ces deux comparaisons est fausse, alors le programme affiche un échec. On souhaite donc trouver un résultat qui réponde à tous ces critères.
Étape 2: Création d'un solveur
Au lieu d’utiliser LD_PRELOAD, on va écrire un logiciel bruteforçant chaque caractère car la complexité est de 0xFF types de caractères, multipliée par 43 caractères. Soit 11264 possibilités. C’est quasiment instantané pour un ordinateur.
On se retrouve avec le solveur suivant :
hardcoded_child_data = bytearray.fromhex("1313E185239B20F32493F6FEBE1BCD28207CB50A574F9BC47E87DAB68E519CA62E71DE016763CA9E07DA6B00")
harcoded_result = bytearray.fromhex("E2140000AA190000882F0000D23300000C2700006E3C0000B92B00006C280000A52D00002C62000020250000A0260000285500003C190000702F0000C9040000901A0000FD0C00002E5A0000980C0000BE150000F00500004C6C0000C02D00003F0C000018610000FB2C000008520000A7250000320500009D620000201C0000801B000044020000984C0000300900007610000044160000884400007F210000500A00006B500000BE0A00000000000000000000000000000000000000000000")
end_cmp = bytearray.fromhex("020000001200000040000000010000000000000002000000200000003000000004000000030000003000000030000000240000001B0000000000000020000000200000005C0000003500000000000000510000004F00000010000000000000005E000000000000001000000024000000020000005100000000000000200000002E00000070000000520000000000000021000000430000004200000010000000000000005200000069000000")
result = bytearray(44)
for i in range(44):
for j in range(0xFF):
tmp_val = j*(j^hardcoded_child_data[i])
tmp_target = int.from_bytes(harcoded_result[i*4:(i*4)+4], byteorder="little")
if tmp_val == tmp_target:
tmp_val
tmp_cmp = int.from_bytes(end_cmp[i*4:(i*4)+4], byteorder="little")
if (hardcoded_child_data[i] & j) == tmp_cmp:
result[i] = j
print(i, chr(j))
print(result.decode())
Étape 3 : Validation du challenge
On exécute le solveur et on obtient :
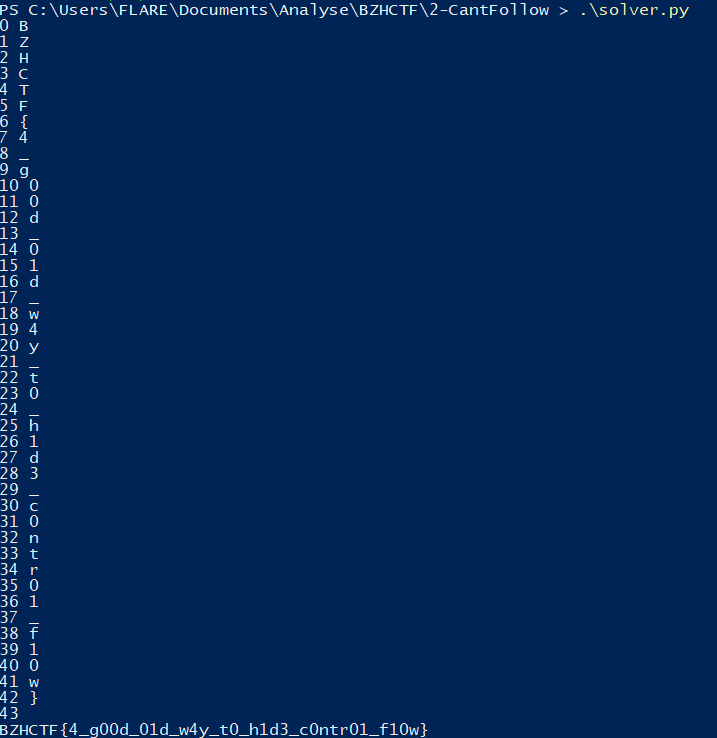
BZHCTF{4_g00d_01d_w4y_t0_h1d3_c0ntr01_f10w} et valider le challenge ! Conclusion
La présence d’antidebug est extrêmement récurrente dans les challenges, mais aussi dans les programmes légitimes standards et les virus. Il est important de découvrir ce que fait réellement le programme dans ses protections afin de savoir s’il vaut mieux désactiver l’antidebug, résoudre une fonction de façon statique (comme ici, sans exécution) ou si l’utilisation d’une méthode tel qu’LD_PRELOAD est nécessaire pour analyser le programme de façon dynamique sans perdre des fonctionnalités.
3. DontBeAngry
Information sur le challenge
DontBeAngry nous est fourni. Le premier pas consiste à l’analyser avec Detect It Easy: 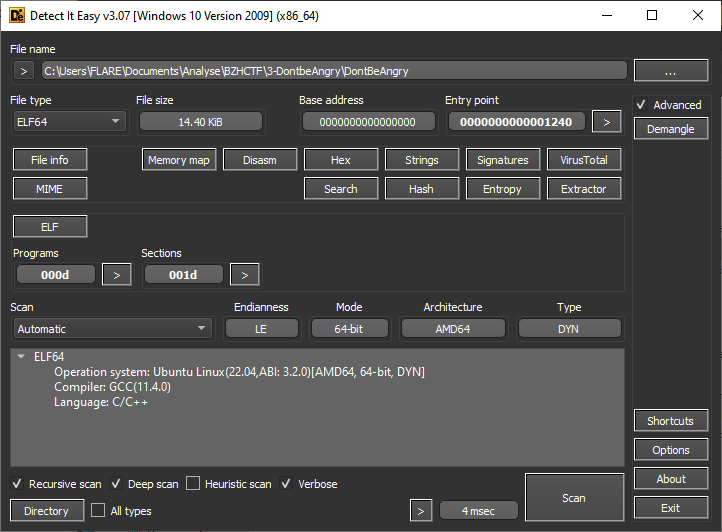
On a ici un fichier binaire exécutable Linux, en 64 bits. Le fichier est linké de façon dynamique, donc les fonctions de bases comme printf, malloc et équivalent seront déjà identifiées lors de la décompilation. Bonne nouvelle !
La résolution de ce challenge va suivre un cheminement spécifique à l’analyse ayant eu lieu lors du BZHCTF. Des subtilités ont été contournées grâce à cette méthode, et il peut être intéressant de comparer ce write up au write up officiel.
Résolution
Solution 1 : Version CTF
Étape 1 : Analyse avec IDA Pro
(La base de données sera déjà commentée afin de gagner du temps, le main n’est pas aussi détaillé à l’origine)
Au lancement de la décompilation, on se retrouve avec ce main :
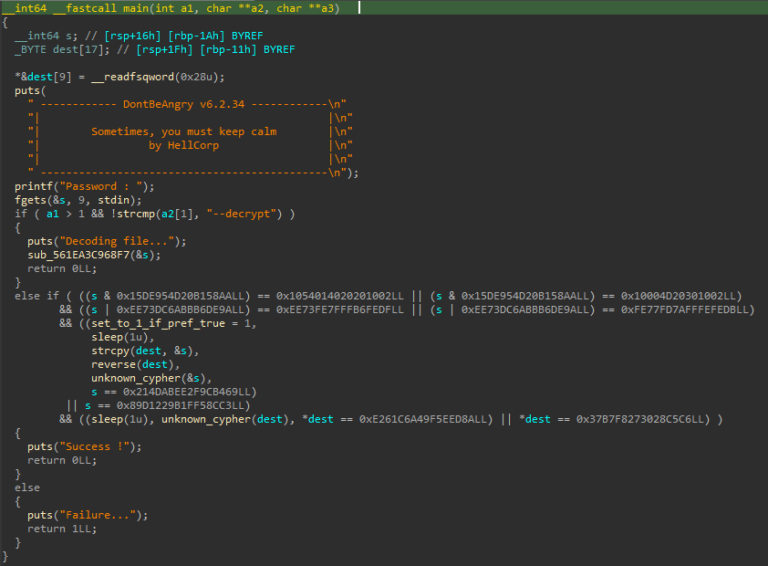
On remarque deux choses. Après la récupération d’un mot de passe de 8 char :
- Le programme peut prendre des arguments. Si l’argument –decrypt est fourni, celui-ci rentre dans la fonction `sub_561EA3C968F7`
- Si aucun argument n’est fourni, alors le mot de passe est testé de multiples façon différentes afin d’être validé.
Étape 2 : Résolution du début de la validation
Afin de commencer à voir les solutions possibles, on va extraire tous les résultats possibles des premières comparaisons du binaire :
else if ( ((s & 0x15DE954D20B158AALL) == 0x1054014020201002LL || (s & 0x15DE954D20B158AALL) == 0x10004D20301002LL)
&& ((s | 0xEE73DC6ABBB6DE9ALL) == 0xEE73FE7FFFB6FEDFLL || (s | 0xEE73DC6ABBB6DE9ALL) == 0xFE77FD7AFFFEFEDBLL)
Pour cela, on utilise Z3, le résolveur de théorème de Microsoft. Ce module python permet de lister les solutions possibles à une équation à multiples inconnues. Or techniquement, le flag de 8 caractères est une équation à 8 inconnues :
from z3 import *
import re
import sys
solver = Solver()
# Create BitVec variables for each bit in the flag
flag_bits = [BitVec(f"flag_bit_{i}", 8) for i in range(8)]
for i in range(8):
solver.add ((flag_bits[i] >=0x20))
solver.add ((flag_bits[i] <=0x7E))
# Combine the bits into a single BitVec object
flag = Concat(*flag_bits)
# Perform bitwise operations on the combined flag
solver.add((((flag & 0x15DE954D20B158AA) == 0x1054014020201002) | ((flag & 0x15DE954D20B158AA) == 0x10004D20301002)))
solver.add((((flag | 0xEE73DC6ABBB6DE9A) == 0xEE73FE7FFFB6FEDF) | ((flag | 0xEE73DC6ABBB6DE9A) == 0xFE77FD7AFFFEFEDB)))
print(solver.check())
nb_sol = 0
letter = ""
while solver.check() == z3.sat:
nb_sol = nb_sol + 1
solution = "Not(And("
m = solver.model()
response = bytearray(8)
for i in m:
if int(str(i)[9], 10) == int(sys.argv[1],10):
solver.add(eval(re.sub(r"flag_bit_(\d+)", lambda match: f"flag_bits[{match.group(1)}]", f"{i} != {m[i]}")))
letter = f"{letter}{chr(m[i].as_long())}"
response[int(str(i)[9], 10)] = int(m[i].as_long())
print(f"{i} == {chr(m[i].as_long())}")
solution = f"{solution} ({i} == {m[i]}),"
print(response.decode())
solution = f"{solution[:-1]}))"
replaced_str = re.sub(r"flag_bit_(\d+)", lambda match: f"flag_bits[{match.group(1)}]", solution)
f2 = eval(replaced_str)
#solver.add(f2)
print(nb_sol)
print(int(sys.argv[1],10), letter)
Ce solveur peut lister les caractères imprimables possibles pour chaque lettres du flag.
On se retrouve donc avec la liste suivante :
CGWS
0264
h0264lnj
dofgwuem}tln~|v
P_]}pRr
!"*bjai)
T01tuU
P `b"B@02rp8:ZXxzR(*JHhj
Étape 3: Le coup de chance
- Le flag est généralement cohérent. Il représente probablement une passphrase plus qu’une suite aléatoire de caractères
- Le flag est généralement en l33t. C’est à dire que certains caractères peuvent être remplacés par des chiffres ou des caractères spéciaux.
- Les espaces sont toujours représentés par des underscores.
- Le flag est souvent composé de mots en anglais.
G00d a été le premier à être supposé. Ensuite, par déduction des potentiels mots suivant good, j0b a été trouvé ensuite. Étape 4: Validation du challenge
G00d_j0b, on peut maintenant vérifier notre théorie, et découvrir que nous avons trouvé le bon flag !
On relance le programme avec l’argument –decrypt, et on obtient l’image suivante : 
BZHCTF{tim3d_c0ntr0l_fl0w} et valider le challenge ! Solution 2 : Version vulnérabilité du chiffrement
Étape 1 : Analyse avec IDA Pro
sub_561EA3C968F7, renommé ici decrypt_file : 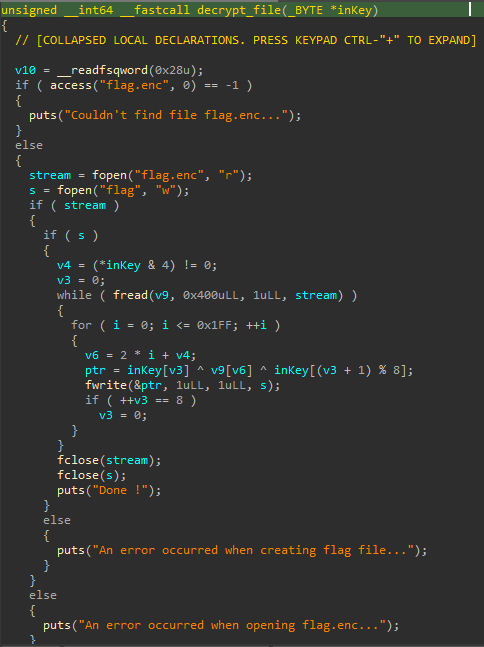
La fonction ouvre flag.enc, puis flag, et va effectuer un déchiffrement à base de xor. avec v6 = 2 * i + v4 on remarque déjà que le déchiffrement ne prend qu’un octet tous les deux octets.
De plus, le xor est effectué entre le caractère chiffré, le caractère du mot de passe, et le caractère suivant du mot de passe. Or, le xor étant associatif et commutatif, inKey[v3] ^ v9[v6] ^ inKey[(v3 + 1) % 8] =v9[v6] ^ (inKey[v3] ^ inKey[(v3 + 1) % 8]). De ce fait, on se retrouve avec un simple xor 8 octets.
En ouvrant le fichier avec un éditeur hexadécimal, on obtient la visualisation suivante :
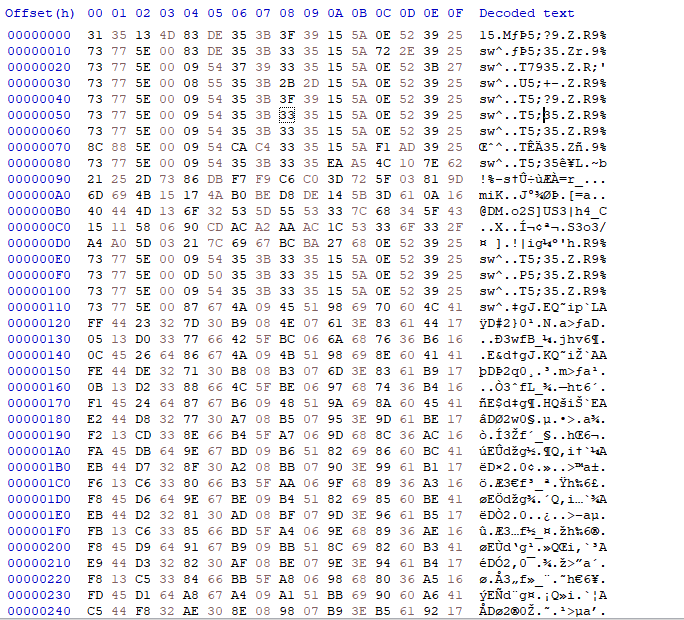
On remarque directement un certain motif de longueur 16 dans le début du fichier. En effectuant un xor la ligne 60 (car c’est celle qui a le plus de caractères en commun avec les précédentes et les suivantes), puis en prenant un octet sur deux, on se retrouve avec un fichier bmp.
L’opération a été effectuée sur cyberchef avec cette recette :
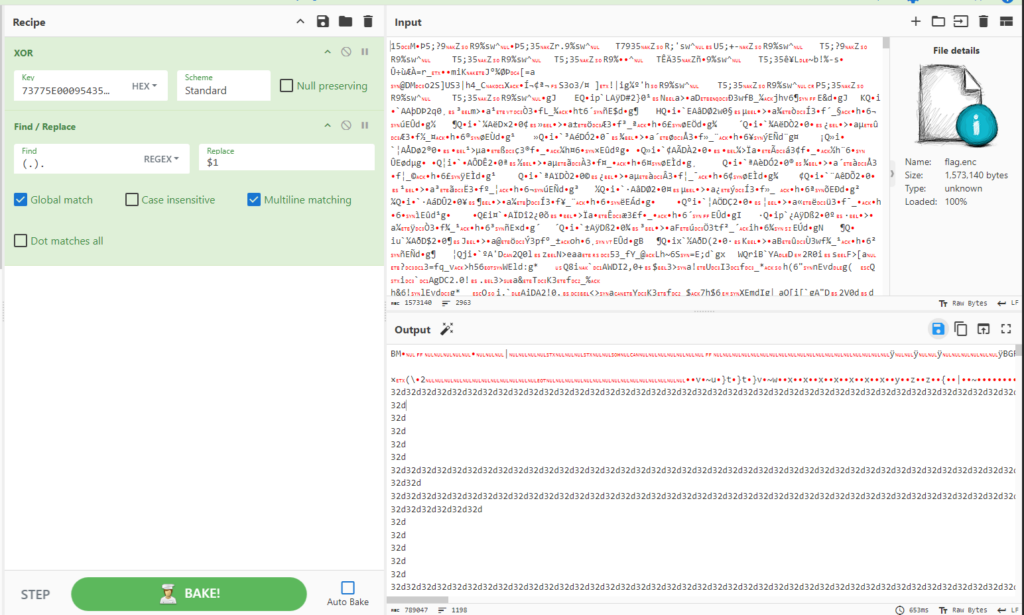
Le fichier bmp résultant est :
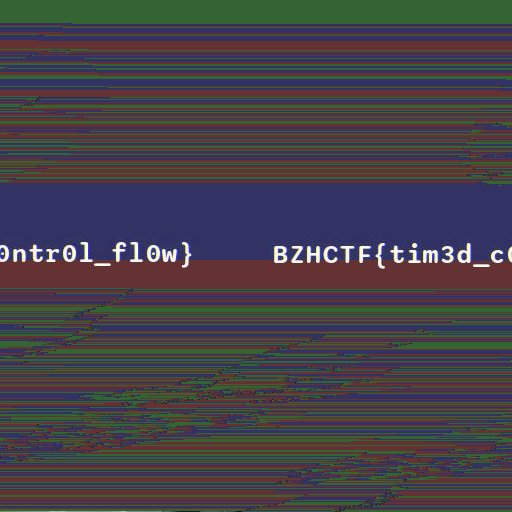
BZHCTF{tim3d_c0ntr0l_fl0w} est lisible.
Le challenge est donc résolu en quelques minutes, sans aucune difficulté réelle. Solution 3 : La vrai solution
La vrai solution consiste à analyser la suite des vérifications après la solution 1. C’est la solution qui aurait été appliquée si le mot de passe n’avait pas été trouvé par chance.
Reprenons le main :
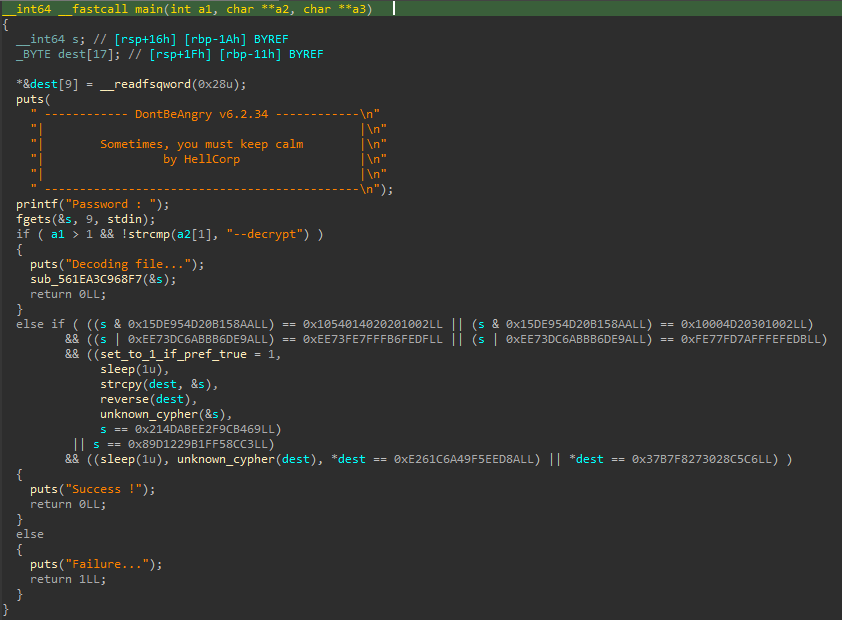
set_to_1_if_pref_true (mal nommé, mais gardé pour représenter le fonctionnement du reverse lors d’un CTF) est passé à 1 si le flag a passé le test précédent :
else if ( ((s & 0x15DE954D20B158AALL) == 0x1054014020201002LL || (s & 0x15DE954D20B158AALL) == 0x10004D20301002LL)
&& ((s | 0xEE73DC6ABBB6DE9ALL) == 0xEE73FE7FFFB6FEDFLL || (s | 0xEE73DC6ABBB6DE9ALL) == 0xFE77FD7AFFFEFEDBLL)
En regardant où est utilisée cette variable, on trouve le handler suivant :
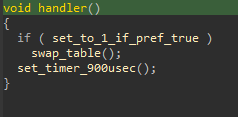
Ce handler est lui-même appelé dans la fonction d’initialisation du programme :
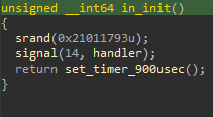
On se retrouve donc avec un handler appelé toutes les 0.9 millisecondes, avec un signal SIGALRM. On remarque aussi qu’une seed est fournie à rand.
Regardons maintenant swap_table :
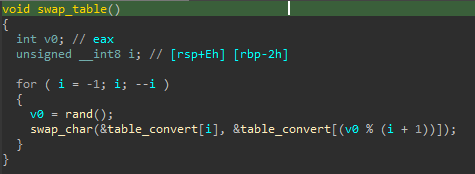
On découvre qu’un mélange d’une table appelée table_convert est effectué le tout depuis une valeur random, mais dont la seed est connue. Intéressant. Retournons donc à notre main, après le set de set_to_1_if_pref_true.
On a un sleep d’une seconde. Or, pendant ce sleep, le SIGALRM va être activé. Il faut donc garder en tête qu’un mélange de la table précédente a été effectué. Ensuite une copie du buffer d’entré est créé, puis l’ordre des lettres est inversé.
Enfin, on a une fonction appelée ici unknown_cypher:
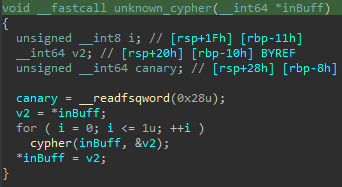
Ok, cette fonction effectue donc une fois la fonction cypher :
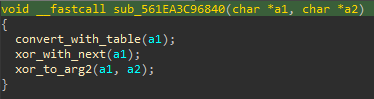
Regardons convert_with_table:
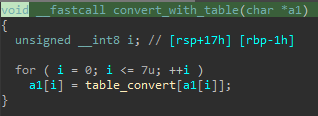
On se retrouve donc avec une fonction de chiffrement maison. Une fois effectué, une vérification est réalisée sur le résultat. Si le résultat est validé, un nouveau sleep est effectué (donc de nouveau un mélange !), puis un chiffrement sur la version inversée du buffer d’entrée, et une vérification de nouveau.
En extrayant les tables après les mélanges, on peut implémenter un solveur basé sur le début de résultat de z3.
Pour obtenir une solution complète avec cette méthode, n’hésitez pas à regarder un autre write up !
Conclusion
Comme présenté dans les solutions 1 et 2, même les challenges notés comme complexes peuvent contenir un petit défaut, les rendant réalisables plus facilement que prévu. Cependant, cela demande de réfléchir hors de la solution linéaire, ce qui est bien plus compliqué à deux heures du matin. Il peut être intéressant de prendre une pause et/ou de passer sur un autre challenge temporairement, afin de pouvoir remarquer des solutions qui sortent du cheminement initial que vous avez pris.
Les deux premières solutions prennent entre 5 et 30 minutes à être analysées et implémentées. Même si la première solution demande une certaine vulnérabilité dans le format de la passphrase, la deuxième est applicable dans beaucoup plus de cas. La 3ème solution demande des compétences de reverse bien supérieures, et plusieurs heures de travail ce qui peut s’avérer coûteux pour un CTF (seulement 15% à 25% des équipes ont résolu ce challenge).
4. MMM
Information sur le challenge
Module.so nous est fourni. Le premier pas consiste à l’analyser avec Detect It Easy: 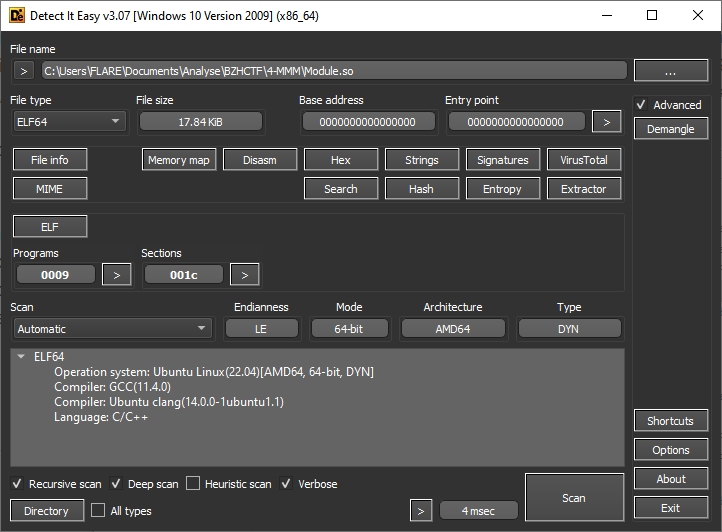
On a ici un fichier binaire Linux, en 64 bits. Le fichier a pour extension .so, c’est donc un fichier de bibliothèque partagée. En regardant les chaines de caractères, on se retrouve avec des mots clefs comme PyArg, PyInit, PyModule…
Et surtout un indice : MMM stands for Module Maze Madness :-)
Le fichier est donc probablement un module python !
Résolution
Étape 1 : Analyse avec IDA Pro
On remarque rapidement que le programme n’a pas de main principal, mais a un grand nombre d’exports :
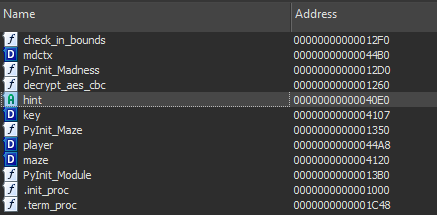
Là, pour l’exemple nous allons considérer que nous avons peu de connaissances sur les modules python compilés (ce qui était mon cas lors du CTF).
Étape 2 : Chargement du module python
Après quelques recherches sur internet, on peut trouver un code python afin d’importer un module .so dans un script python :
def __bootstrap__():
global __bootstrap__, __loader__, __file__
import sys, pkg_resources, imp
__file__ = pkg_resources.resource_filename(__name__,'Module.so')
__loader__ = None; del __bootstrap__, __loader__
imp.load_dynamic(__name__,__file__)
__bootstrap__()
Ensuite, on peut facilement importer le module dans un script python, et extraire la liste des fonctions utilisables dans le module :
import Module
def print_exports(module_name):
# Get all names in the module's namespace
names = dir(eval(module_name))
# Filter out unwanted items
filtered_names = [name for name in names if not name.startswith('_') and not name == '__name__']
print(f"\nExports from {module_name}:")
for name in filtered_names:
print(name)
# Example usage
print("Module loaded! Export that can be used: ")
print('\n-----------\nModule:')
print_exports('Module')
On obtient :
Module loaded! Export that can be used:
-----------
Module:
Exports from Module:
check
welcome
En allant regarder ces fonctions dans le module, on voit ceci :
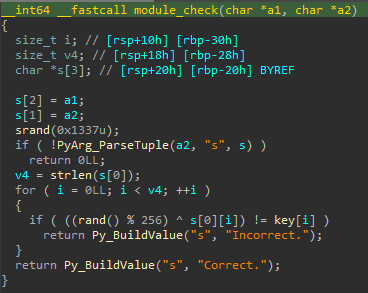
Étape 3: Résolution de module_check
La fonction est une comparaison entre la chaine passée en argument, xorée avec des valeurs issues de rand précédemment seedés, et une clef codée en dur. Cette partie peut facilement être résolue car la chaine passée en argument est aussi équivalente à la clef codée en dur xorée avec les valeurs de random (associativité du xor). On peut donc écrire un petit code pour résoudre cela :
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
void hexStringToByteArray(const char* hexString, uint8_t* byteArray, int len) ;
void hexStringToByteArray(const char* hexString, uint8_t* byteArray, int len) {
for(size_t i = 0; i < len; i += 2) {
// Extract two characters at a time
char hexPair[3] = {hexString[i], hexString[i+1], '\0'};
// Convert the hex pair to an integer
int intValue = 0;
sscanf(hexPair, "%02x", &intValue);
// Store the integer in the byte array
byteArray[i / 2] = (uint8_t)intValue;
}
}
int main() {
// Seed the random number generator with 0x1337
srand(0x1337);
const char* hexString = "67746A949534AC3D80198200";
int length = strlen(hexString);
uint8_t* ByteArray = malloc(length/2);
hexStringToByteArray(hexString, ByteArray, length);
for(int i = 0; i < length; i++) {
unsigned int dwordValue = ((unsigned int)rand())%256;
printf("%x\n", ByteArray[i]^dwordValue);
}
/*
for(int i = 0; i < 100; i++) {
// Cast the result of rand() to unsigned int to treat it as a DWORD
unsigned int dwordValue = ((unsigned int)rand())%256;
printf("%x\n", dwordValue);
}*/
return 0;
}
(Le code a été développé en C afin d’assurer l’utilisation de la même fonction d’aléa en appelant directement rand depuis la libc)
On obtient le résultat suivant (après décodage de l’ASCII) :
BZHCTF{S33!
On a donc le début du flag !
L’autre fonction de module, welcome, affiche juste du texte qui ne semble pas très utile pour le moment…
Étape 4: Résolution du labyrinthe
De ce fait, comment charger la suite des informations ? On tombe sur un export nommé maze, contenant ceci :
00000101010101010101010101010101000100000001000000000000000101000100010001000101010101000101000000010000000100000000000101000100010001010101010001000101000100010000000100010001000101000100010101000100010101000101000100000001000100000000000101010101010101010100010101010101000000010001000000010000000101000100010001010100010101000101000100000001000000000001000101010100010101000101010101000101000000000000000000000000000201010101010101010101010101010100000000000000
Cette valeur est utilisée dans plusieurs fonctions, dont move_right() et check_solved(). En regardant move_right(), on découvre que la fonction vérifie si le joueur est dans les limites du labyrinthe :
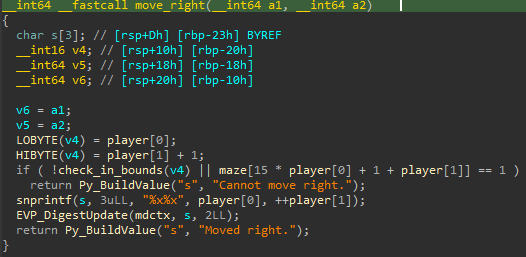
Ensuite, un calcul crypto est effectué dans EVP_DigestUpdate.
Bon, déjà, essayons de rendre le labyrinthe fonctionnel. On colle la chaine dans notepad++, et on effectue les fonctions Replace suivantes :
([012]{30}) => $1\n (on créé un retour à la ligne tous les 30 caractères)
01 => # (on remplace les 01 par des « murs »)
00 => . (on remplace les 00 par des « chemins »)
02 => E (on remplace les 02 par des « E » pour représenter la sortie)
On obtient donc le labyrinthe suivant :
..#############
#.#...#.......#
#.#.#.#.#####.#
#...#...#.....#
#.#.#.#####.#.#
#.#.#...#.#.#.#
#.#.###.#.###.#
#.#...#.#.....#
#########.#####
#...#.#...#...#
#.#.#.###.###.#
#.#...#.....#.#
###.###.#####.#
#.............E
###############
.......
check_solved et de voir le résultat ! Étape 5 : Chargement des fonctions de Maze
.data : 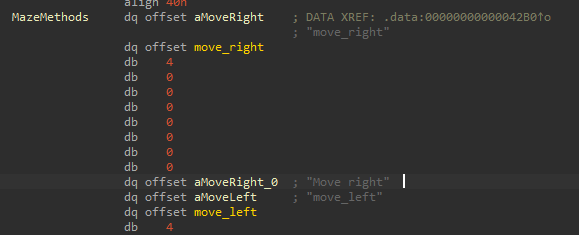
Comparons ça à l’appel des fonctions que nous connaissons, tel que module_check :
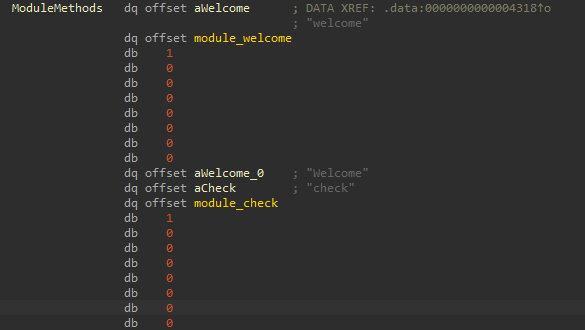
Ici, on découvre quelque chose nommé ModuleMethods, et MazeMethods. Ces methods ressemblent à des méthodes qu’une classe dans un langage orienté objet pourrait avoir.
Ces méthodes semblent faire partie d’un objet plus large. Hors dans les exports, on a les fonctions PyInit_Module et PyInit_Maze. Ces deux fonctions pointent justement un objet plus large. On peut aussi voir une fonction PyInit_Madness. Maintenant on se doute que le fichier semble contenir plusieurs modules, avec plusieurs méthodes. Or, dans notre fonction bootstrap permettant d’importer le module, on ne donne pas d’information sur le module à importer… Mise à part son nom !
Afin de vérifier notre théorie, on copie le fichier Module.so, on le renomme Maze.so, on crée un fichier Maze.py contenant le bootstrap, et on importe Maze. Au passage, on copie et renomme aussi le Module en Madness.so.
Ensuite, on importe les modules et on regarde leur fonctions exportées :
Module loaded! Export that can be used:
-----------
Module:
Exports from Module:
check
welcome
-----------
Maze:
Exports from Maze:
check_solved
move_down
move_left
move_right
move_up
-----------
Madness:
Exports from Madness:
get_flag
Étape 6 : Rédaction du solveur
check_solved. Si les déplacements ont bien été effectués, check_solved retourne:
Solved. Here is your reward: 6abf0cd1ac959be725c67df3479cd2cd.
Bon, on se doute que cette « récompense » est à entrer dans Madness.get_flag()
import sys
import types
import Module
import Maze
import Madness
def print_exports(module_name):
# Get all names in the module's namespace
names = dir(eval(module_name))
# Filter out unwanted items
filtered_names = [name for name in names if not name.startswith('_') and not name == '__name__']
print(f"\nExports from {module_name}:")
for name in filtered_names:
print(name)
# Example usage
print("Module loaded! Export that can be used: ")
print('\n-----------\nModule:')
print_exports('Module')
print('\n-----------\nMaze:')
print_exports('Maze')
print('\n-----------\nMadness:')
print_exports('Madness')
print(" call:\n")
print(Maze.move_right())
for i in range(3):
print(Maze.move_down())
for i in range(2):
print(Maze.move_right())
for i in range(2):
print(Maze.move_up())
for i in range(2):
print(Maze.move_right())
for i in range(2):
print(Maze.move_down())
for i in range(2):
print(Maze.move_right())
for i in range(2):
print(Maze.move_up())
for i in range(6):
print(Maze.move_right())
for i in range(6):
print(Maze.move_down())
for i in range(4):
print(Maze.move_left())
for i in range(4):
print(Maze.move_down())
for i in range(2):
print(Maze.move_left())
for i in range(2):
print(Maze.move_down())
for i in range(7):
print(Maze.move_right())
result = Maze.check_solved()
print(result)
result_val = result[29:]
print(result_val)
result_byte = bytes.fromhex(result_val)
result = Madness.get_flag(result_byte)
Étape 7 : Validation du challenge
On exécute le solveur et on obtient :
Good job! Append this to your flag! _CPyth0n_M0dul3s_4r3_fuN_aR3nt_theY?}
Pour rappel, dans l’étape 3, nous avions trouvé :
BZHCTF{S33!
On peut donc valider le challenge avec :
BZHCTF{S33!_CPyth0n_M0dul3s_4r3_fuN_aR3nt_theY?}
Conclusion
Ce challenge est très intéressant afin de développer ses compétences dans le reverse de module Python compilé. La subtilité du renommage du fichier demande soit une recherche très précise sur internet, ce qui est très compliqué quand on ne sait pas exactement ce que l’on cherche, soit d’avoir l’esprit ouvert et de chercher avec les informations à notre disposition, même si cela peut sembler « stupide ». Quel que soit le challenge, si le test n’est pas trop chronophage, essayez le, vous pouvez obtenir des indices importants pour en déduire la solution.









